What is Big Data and Why Do We Need It?
We live in the golden age of data, where terabytes and even petabytes are being sent, shared, collected, uploaded, and downloaded across various platforms around the globe on a daily basis. The quantities are so vast it’s difficult to mentally grasp the numbers that are involved.

Figure #1 above highlights just the volumes from Social Media alone. Toss in data pouring in from Ecommerce, the Cloud, streaming services, among others, and now you are talking really Big Data! And just to keep things interesting, data can be in many formats like images, flat files, audio etc. whose structure and format may not be the same.
Billions of dollars are spent annually to collect and store Big Data. The value of Big Data comes from its analysis to gain meaningful insights for business intelligence. With Big Data comes new trends such as Starbucks deploying Chatbots to take orders or MasterCard letting them reply to customer service transactional queries in such a personalized way that people have no idea they are chatting with a robot.
Big Data Testing
Data quality, functional correctness and performance are all important factors along the Big Data processing highway that must work properly and data quality assurance is an increasingly crucial aspect in its successful implementation. Ensuring data quality can be iterative and time consuming due to high volumes, variety, and velocity of the data involved. Also, the variety and velocity of data can lead to potential issues such as source data errors, mixed data types, unstructured or semi-structured data, and unexpected results from product exception handling. Ensuring data quality is essential for companies to successfully leverage results from business intelligence and analytics in making product decisions. Without data quality, making decisions and gaining insights might not only go astray, but be in the exact opposite direction and hurt the business.
Data quality has always been an issue and an obstacle of varying degrees depending on your viewpoint and usage. Frequently, there are different perceptions of data quality between the data consumer and data processing team. The 3 Vs’ (Volume, Velocity, and Variety) nature of the data processing has made it much harder to close the gap between good data and bad data.
To ensure data quality, we break Big Data testing down into the following areas; Data Profiling, Data Preparation, and Data Validation (See Fig.#2 below).
Figure 2 – Big Data Testing Schematic
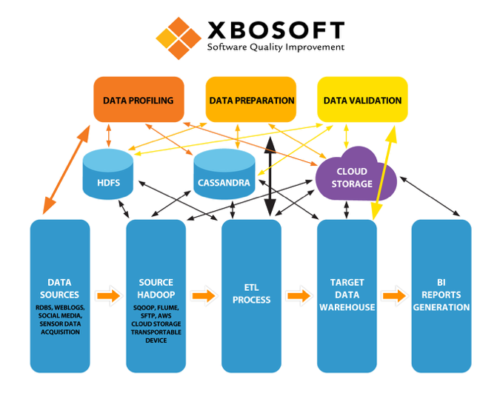
At XBOSoft, our Big Data testing service is focused on the Data Validation component. The testing involves three stages as outlined below:
1. Data Validation: Understandably, this is one of the most important components of data collection. To ensure data integrity and accuracy, it is important that it is validated. For this purpose, sources need to be checked and validated against actual business requirements. The initial data will be fed into Hadoop Distributed File System (HDFS), where each partition will be checked thoroughly, followed by copying them into different data units. Tools like Datameer, Talent and Informatica are used for step-by-step validation.
Data validation is also known as pre-Hadoop testing, and ascertains that the collected data is from the stated resources. Once that step is completed, it is then pushed into the Hadoop testing system for tallying with the source data.
2. Process Validation: Once the data and the source are matched, they will be pushed to the right location. This is the Business Logic validation or Process Validation, where the tester verifies the business logic, node by node, and then verifies it against different nodes. Business Logic Validation is the validation of Map Reduce, the heart of Hadoop.
The tester will validate the Map-Reduce process and check if the key-value pair is generated correctly. Through “reduce” operation, the aggregation and consolidation of data is validated.
3. Output Validation: Output validation is the next important component. Here the generated data is loaded into the downstream system. This could be a data repository where the data goes through analysis and further processing. This is then further checked to make sure the data is not distorted by comparing HDFS file system with target data.
Big Data is big and will continue to become bigger. Bigger in the sense of size as more data sources come to fruition as sensors and other applications come online. More importantly, Big Data will become “bigger” in terms of importance due to the insights that can be gained. These insights can provide great value to a company trying to understand its users or customers better and to optimize their service and product offerings in a personalized manner. Yet the old caveat “garbage in garbage out” applies more than ever to Big Data. That’s where Big Data Testing comes in. If the data is not validated, it can lead analysts astray leading to information and insights that are not only inaccurate but perhaps in the opposite direction. Don’t make the mistake of assuming your data is valid and accurate. Let XBOSoft support your Big Data initiatives with our Big Data testing services.
Leave A Comment